Introduction to Diffusion Models (Part III. Diffusion Process)
Abstract.
This tutorial delves into the concept of diffusion models, focusing primarily on the diffusion process. Using a clear-to-noisy image progression as an example, it explains the forward diffusion process where images gradually become more distorted with the introduction of Gaussian noise. The mathematical foundations of the process are explored, relating the process to Gaussian distribution properties. We then transition to the reverse diffusion process, where the goal is to revert from a noisy image back to its original form. Analogies are provided for clearer understanding, such as the imagery of adding and removing sand from a glass of water. Key components of the related equations, including the mean and variance, are broken down to provide intuition behind the mathematical models. The tutorial hints at the upcoming section which will address the training mechanisms of diffusion models.
Table of Contents
- Forward Diffusion Process: From Image to Noise
- Understanding the core concepts
- The role of Gaussian noise
- Mathematical formulation of the process - The Nature of the Noise: Gaussian Distribution
- Mean (μ): Center of the Noise
- Variance (Σ): Spread of the Noise - Iterative Refinement in Diffusion
- The Big Picture
- The power of the diffusion model
- Scaling factor and its role in the mean - Reverse Diffusion: From Noise to Image
- Visual perspective of the reverse process
- Decoding the reverse diffusion equation - Coming Next: Training Diffusion Models
Learning Outcomes
- Understanding Diffusion Models: Gain a clear comprehension of diffusion models (forward and reverse) and their applications in transforming data through iterative processes.
- Probabilistic Intuition: Develop an intuitive grasp of the probabilistic foundations underlying diffusion models, including Gaussian noise and conditional probability distributions.
- Reparametrization Trick: Learn how to leverage the reparametrization trick for efficient sampling in diffusion models, facilitating the generation of diverse and controlled data transformations.

Forward Diffusion Process: From Image to Noise
Figure 1 presents a visual representation of the diffusion process model. The process commences with a clear, original image represented by x0. Gaussian noise is systematically introduced at each step as we progress along the sequence from x0 to xT. This iterative application of noise transforms the image gradually. When we reach xt and further towards xT, the image becomes increasingly distorted or pixelated, illustrating the cumulative effect of the noise.
The function q(xt∣xt−1) indicates the transition from one state to the next. It can be interpreted as the mechanism or rule by which the Gaussian noise is applied to the image at each time step. The objective of this model could be to study the effects of noise on data, to simulate certain real-world scenarios, or to assess the robustness of image processing algorithms against noise.

Mathematically, This diffusion process can be formulated as follows.

This revolves around the Gaussian (or Normal) distribution, a foundational concept in statistics and machine learning. This conditional probability distribution describes how x(t) (the image at time t) depends on x(t−1) (the image at the previous step).
The Nature of the Noise: Gaussian Distribution
Mean (μ): Center of the Noise. The mean μt in a Gaussian distribution indicates where the center of our noise is. Here, it’s determined by:

So, the main part of our noise (its ‘center’) is just a scaled version of the previous image. The scaling factor is (1−βt).
This means we’re slightly shifting the image by a factor that depends on βt, with βt controlling how much we deviate from the original.
Variance (Σ): Spread of the Noise. The variance, denoted by Σt here, tells us about the spread or dispersion of our noise. It’s described by:
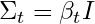
Where I is the identity matrix. It ensures that the noise is added independently to each pixel or feature of the image. The term βt scales this noise. A larger βt means more noise, while a smaller one means less.
The Big Picture: Iterative Refinement
So, at each step t, the image is slightly shifted (according to the mean) and then noise is added around this shifted version (according to the variance). Over multiple steps, this leads to an image that’s increasingly noisy. But remember, it’s not random noise; it’s structured and based on the original image.
The power of the diffusion model lies in reversing this process. By training on this forward noise process, the model learns to do the reverse: starting from a noisy image, it iteratively refines and ‘denoises’ it to produce a clear, coherent sample.
Question: Why do we need the scaling factor (1−βt) to shift the mean?
The mean deviation from the image in the diffusion process is essential for achieving the generative capability of the model. Let’s break this down with a combination of intuition and technical explanation.
Intuitive Perspective: Customizing a Basic Car Model
Imagine you’re at a car manufacturing workshop with a basic car model on display. This car is plain, with no additional features — just four wheels, a body, and essential components. Think of this basic car model as our initial image or starting point.
Now, you’re tasked with creating various custom versions of this basic car model. You do this iteratively, making slight changes in each step.
In the first iteration, you might add tinted windows. Next, you could introduce a spoiler, modify the bumper, change the wheel design, or add racing stripes. These alterations are similar to the “noise” or changes we’re introducing to our image.
While each change deviates from the basic model, it’s still clearly recognizable as a vehicle. By keeping the changes controlled and rooted in the original design, we ensure that we always end up with a functional and recognizable vehicle, even after numerous customizations.
The basic car model is the reference point in our mathematical equation, and the mean (μ) represents our expected or “average” outcome at each step. By ensuring our changes are small and controlled (scaled by βt), we guarantee that the resultant design, though unique, still retains the essence of a vehicle.
Technical Perspective: Iterative Refinement
The mean, μt, in the diffusion process, represents where we expect our image to be after adding noise at time t. It’s calculated as
The term (1−βt) acts as a tether, ensuring that our image doesn’t drift too far from its starting point. However, as βt increases, our “tether” allows for more slack, meaning the image can drift slightly.
This drifting is akin to our adjustments to the clay sculpture. If βt is too high right from the start, our changes to the initial vehicle model would be drastic, and we’d lose resemblance to the original vehicle structure. But by controlling this drift using βt, we ensure that our changes, while making the vehicle image different, still retain its essence and are recognized as a vehicle.
Over time, this controlled deviation allows the model to explore and generate a diverse set of images, much like how our controlled adjustments can lead to various faces from our original clay sculpture.
Setting the Stage: Multi-dimensional Scenario
When working in a multi-dimensional space, I denotes the identity matrix, which, in this context, implies each dimension has a consistent standard deviation βt. Now, q(xt∣xt−1) is a conditional normal distribution described by the mean μt and variance Σt.
Tractability of Progression
Starting from our initial data x0 and progressing to xT, you can represent the entire transformation journey. This journey can be visualized as:

The colon symbol (:) here just means that we are applying the function q across all timesteps from 1 to T.
However, a challenge arises: If you wanted to sample xt for say t=500 (before reaching T), you’d have to apply the function 500 times. That’s inefficient!
Is there a better way?
The Reparametrization Trick
Enter the reparametrization trick, a handy method that simplifies this process. Instead of working with βt, we introduce αt = 1−βt and its cumulative product up to time ˉαtˉ. This trick allows us to express xt in terms of the initial point 0x0 and some noise �ϵ.
Using the trick, a sample xt can be derived directly as:
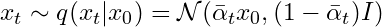
With βt pre-defined, we can calculate αt and ˉαtˉ for all timesteps beforehand. Now, to obtain a sample xt at any timestep, just sample the noise ϵ and plug it into the equation above.
In layman’s terms, using the car analogy, it’s like being able to recreate any customized version of the car without having to remember all the previous customizations. Just the basic model and the current set of customizations are enough.
Starting with a familiar analogy…
Imagine you have a remote-controlled toy car, but instead of directly steering the car, you input commands into a computer, which then processes the commands and controls the car. The reparametrization trick is somewhat analogous to this process: rather than directly sampling from a distribution, we use another route to achieve our goal.
Why this Reparametrization method?
You might wonder: Why go through this roundabout way? Because it’s computationally more efficient! Once you’ve calculated αt and ˉαtˉ, you can quickly generate a sample at any timestep without retracing every single previous step. This efficiency is like fast-forwarding through a movie to any scene without watching everything leading up to it.
Reverse Diffusion: From Noise to Image
Just as diffusion can take a clear image and evolve it into a noisy version, the reverse process seeks to start from a noisy image and trace its steps backward, regressing towards the original. The visualization in Figure 1 illustrates this “time-travel”, effectively a process of de-noising or reconstruction.
Figure 1 showcases the flow. You begin with a highly diffused image, represented by xT. The challenge now is to “un-noise” this image, moving sequentially in reverse from xT to x0. The process is represented by p(xt−1∣xt), indicating the probabilistic rule or mechanism that governs this backward journey.

The Visual Perspective
- Starting Point (xT): This is the distorted or noisy image. If you think of the diffusion process as gradually adding sand to a clear glass of water, then this is our glass filled with sand.
- Intermediate States (xt, xt−1, …): These are the steps between the completely distorted image and the original, where we systematically remove the noise. Using our analogy, we’re slowly removing the sand from our water, making it clearer with each step.
- End Point (x0): This is our aim — the original, undistorted image. In the analogy, it’s our clear glass of water.
Understanding the Functions
- q(xt|xt−1): This represents the forward diffusion process, guiding how we transition from one state to the next. Think of it as the rule by which we added sand (noise) to our glass of water (image).
- p(xt−1|xt): This is the heart of the reverse diffusion. It’s the rule that dictates how we trace our steps back, effectively removing the noise. It’s our method for taking the sand out of the water.
The Big Picture.
The reverse diffusion process, in essence, offers a journey of reconstruction. It showcases the transformative power of probabilistic models in navigating complex transitions. While the forward diffusion is akin to witnessing the blurring of a clear memory, the reverse is a poignant journey of recollection, where scattered pieces are meticulously put together to rebuild the original image.
Decoding the Reverse Diffusion Equation
The Equation below
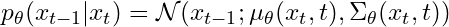
represents the reverse diffusion process at a specific timestep t. Let’s break down the components for a more intuitive understanding:
Components of the Equation:
- pθ(xt−1∣xt): This is the conditional probability distribution of the image at the previous timestep xt−1 given the current image xt. Essentially, it answers the question: “Given the current noisy image xt, what is the likelihood of the previous image being xt−1?”
- N: Stands for the Normal (or Gaussian) distribution. This distribution is used because of its properties, which make it especially useful in many statistical methods, and for its ease of use in mathematical computations.
- μθ(xt,t): This is the mean of the Gaussian distribution, parameterized by θ. It’s a function of the current image xt and the timestep t. In simpler terms, it provides the expected or “average” image at the previous timestep, given our current image. It’s the central point from where the reverse diffusion starts.
- Σθ(xt,t): Represents the Gaussian distribution's variance (or spread), also parameterized by θ. This variance indicates how “spread out” or varied the possible images at xt−1 could be, given xt. A larger variance means that there is a wider range of possible images for xt−1, while a smaller variance indicates that the possible images are closely packed around the mean.
Intuitive Takeaway.
Imagine you’re watching a video in reverse. At any given frame (or timestep t), you have a blurry image (xt). This equation is like a tool that allows you to predict what the previous frame (or xt−1) looked like based on the current one. The mean gives the best guess of that previous frame, while the variance tells how confident or uncertain this prediction is.In the context of reverse diffusion, this equation is central to retracing the steps from a noisy image back to its original, undistorted version.
Coming Next: Training Diffusion Models
In the upcoming section, we will dive deep into the training mechanisms and intricacies involved in optimizing diffusion models. As with any deep learning model, training is a crucial step to ensure the robustness and efficacy of the diffusion process. From loss functions to backpropagation strategies specific to diffusion models, Part IV of this tutorial series will provide a comprehensive guide on the training paradigms to get the best out of your diffusion model. Stay tuned to harness the full potential of these intriguing models!
